
◆◇◆◇◆◇◆官能評価TT通信No.34◆◇◆◇◆◇◆
さて、今回のテーマは「評価事例-後編」です。
簡単に概要をおさらいいたします。
ローカルブランドの缶コーヒーを製造している企業の依頼でした。全国の流通に乗せていくため、大手の商品と味の比較ができる資料を作ってほしい、という内容でした。そして、もうひとつ要望がつけられました。それは、サントリーがWEB上で味のレーダーチャートを公開しており、これにあわせてほしいということでした。
これがこの依頼の最大の難関でした。
カギは実施後の分析にありました。
まず、当時サントリーのHPに掲載されていたレーダーチャートから読み取ったデータを見てみましょう。以後、このデータをSデータとよびます。
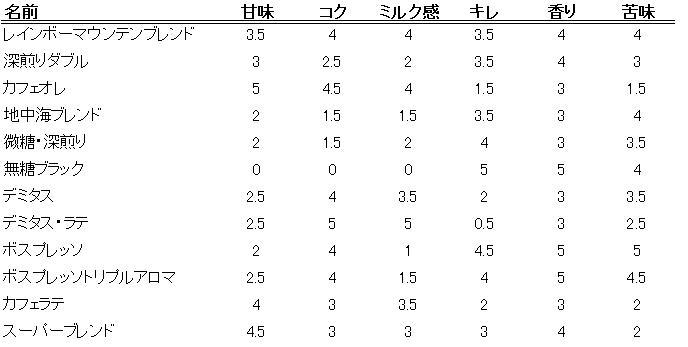
このSデータをもとに「無糖ブラック」「デミタス」「デミタス・ラテ」を対象外として、9銘柄で主成分分析をしました。
主成分1と2の累積寄与率が84%でした。これは主成分1と主成分2の2軸でデータがもつ情報の84%が説明できることを意味します。そこでポジショニングのマップとしては2軸で十分と判断しました。
各コーヒーの主成分得点を元にプロットしたのが次の図です。

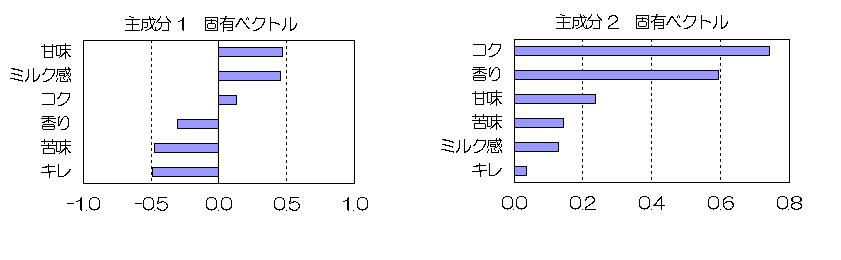
固有ベクトルの結果から軸の意味合いとしては、
縦軸(第1主成分):上に行くほどミルク感が強い⇔下に行くほどコーヒー感が強い
横軸(第2主成分):右に行くほどコクと香りを中心とした総合力が高い
となります。
以上、Sデータをもとに分析した結果です。
次に弊社で行った評価を見てみましょう。以後、弊社の評価データをTTデータとよびます。
【弊社の実施条件】
1.SUBJECT(パネル):選抜訓練されたパネル25名
2.SAMPLE(サンプル):12種+依頼品3種の計15種、常温、白色紙コップ90ml容器に各60ml
3.SCALE(尺度、評価用語):9カテゴリスケール、40属性
4.SITUATION(実施環境):セントラルロケーションテスト(CLT)
5.その他の条件:
1日で評価を実施するスケジュールのため、繰り返し評価は行わず、その代わりパネル数を多くとっている。
今回の最大のポイントは、Sデータの主成分分析得点マップにTTデータを合わせることです。
理想をいえば、Sデータで採用している6属性と同じ評価用語を使って、同じ傾向のデータを取ることでしょう。しかし、前回も書きましたが、評価用語はその まま同じに使ったとしてもサントリーの意図した属性と、弊社パネルが意図した属性が必ずしも同じになるとは限りません。無論、同じになるかもしれません し、ならないかもしれない。こちらとしては1ショット評価(1回限りの評価)なので、分析で対応できるように幅を持ったデータをとりたいと考えました。理想的な方法としてはSPECTRUM DESCRIPTIVE ANALYSISのようにリファレンスと数値を一致させる方法もありますが、訓練にコストと時間がかかるため現実的ではありません。
ところで本当に同じ評価用語でも結果が同じになるとは限らないのでしょうか。
実際にSデータの6評価用語とTTデータの類似の6評価用語の単相関を見てみましょう。
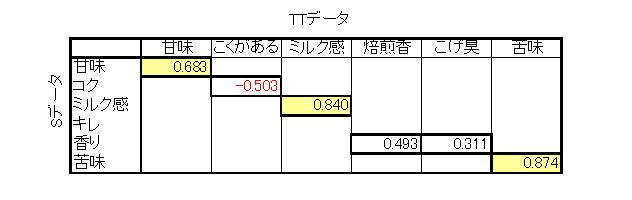
QDAでは評価用語は参加パネルによって作られるので必ずしもSデータと同じ用語とはなっていません。例えば“キレ”という用語は採用されませんでした。“香り”についても“焙煎香”と“こげ臭”に分けて採用されました。
単相関の結果を見てみると、“コク”に関しては逆の相関となっていました。つまり、サントリーの意図する“コク”と今回のパネルが意図する“こくがある”は同じではないということです。“香り”に関しても一致しているとはいえません。
一方、“甘味”は弱い相関、“ミルク感”、“苦味”については相関があります。この3種はブレの少ないコーヒー評価用語として消費者パネル(嗜好型パネル)でも使用できる用語でしょう。
残念ながら、予想通り今回のパネルの評価用語とサントリーの評価用語とは一致しないことがわかりました。
付け加えておきますが、各評価用語をきちんと定義づけして、適切な標準見本を設定してあげれば再現は可能です。サントリーが意図する“コク”の定義とそれを適切に表す標準見本があれば再現できたでしょう。しかし、問題はそのような情報を開示していただくのが難しいだろうということです。
とはいえ、Sデータのマップに載せるという目的からすればたいした問題ではありません。
狙いはサントリーのデータに合わせたマッピングを作成することです。
同一マップに表現できたかどうかの判断は、TTデータで作成したサントリー製品9種のマップ上の位置関係が、Sデータによって作成されたマップ上の位置関係と同等であればOKとすることとしました。
位置関係の同等性の判断は、各軸の製品順位が一致するかどうかで判断しました。事前に行ったSデータの分析から、「微糖・深煎り」と「地中海ブレンド」は2軸とも、「ボスプレッソ」と「ボスプレッソトリプルアロマ」は横軸において近接しているため、この4商品2組については順位が逆転してもOKとすることとしました。
分析のポイントは2つです。
1.合わせる対象をSデータの主成分得点にする
2.分析手法にはPLS回帰分析を使う
最初のポイントは、合わせる対象を何にするかです。まず思いつくのがSデータの評価用語の各々を目的変数として何らかの予測式 を立てる方法です(例:“甘味”=a1דまろやかさ”+a2דミルク感”など)。しかし、この方法には問題があります。マッピングするには予測式の結 果をさらに主成分分析をかけることになりますが、主成分分析はちょっとしたデータの変化でも軸が反転します。そこで最終的にマッピングに使う主成分得点を 合わせる対象(目的変数)にすることでロバスト性を確保しました。
次に、分析手法に何を使うかというポイントです。通常、このような場合は主成分得点を目的変数とし、TTデータのいくつかの評 価用語を説明変数として重回帰分析をすることを考えるでしょう。しかし、予測だけならもっとよい方法があります。それがPLS回帰分析と呼ばれる方法で す。重回帰分析は説明変数の間に高い相関を持つ場合は、つまり共線性を持つ場合はデータがすこし変化しただけでモデル平面が動いてしまい予測モデルとして は使えません。また、説明変数の数にも制約があります。一方、PLSは説明変数の数が多くても、互いに相関が高くても大丈夫です。
PLSについての理論的説明と実際の解析についてはこちらを参照ください。フリーウェアの統計パッケージ「R」による解析の説明があります。
普段はエクセルとRでほとんど処理してしまうのですが、今回のPLSはSAS社JMPの力を借りることにしました。
JMPは実験計画の設計から分析まで一貫したプロセスをもち、PLSやIRT、その他豊富な分析手法が最初から含まれているコストパフォーマンス の高いパッケージだと思います。SPSSは手法ごとにオプションを購入すると結局高くついてしまうのでいろいろやってみたい方にはお薦めです。但し、 ちょっと操作になれないと分析にたどり着けないことがありますが、添付の入門書を一度やってみればすぐ扱えるようになるでしょう。強いて不都合を挙げれば Tukeyの多重比較のp値が表示されないことでしょうか(Dunnetはp値が表示されます)。
一応、SPSSもマーケティングデータの処理の時には活躍しております。
結局、目的にあったソフトウェアを使うのが一番ということですね。
さて、JMPのPLS分析で目的変数にSデータの主成分得点を、説明変数に評価用語全部を入れて分析するとあっという間に予測式が出来上がりました(実際は潜在変数の指定などやることはいろいろあります)。
以上の分析を経て、マッピングをしたのが次の図です。
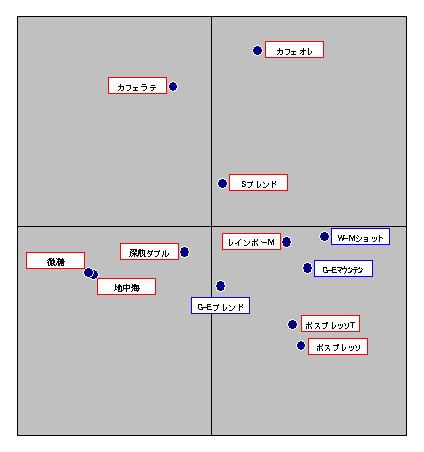
赤枠で囲んだコーヒーがサントリーの商品です。青枠はサントリー以外の大手3商品です。
左図はSデータからブラックとデミタス2種を除いて主成分分析をしてプロットしたものです(再掲)。
右図はTTデータからPLSによって予測式を作成し、サントリー製品9種と大手3商品をプロットしたものです。
目で見た感じでは、サントリーのデータと同様のポジショニングが再現できたような気がします。
そこで位置関係の同等性を判断してみましょう。判断基準は次の2点です。
1.各軸の製品順位が一致しているか
2.「微糖・深煎り」と「地中海ブレンド」は2軸とも、「ボスプレッソ」と「ボスプレッソトリプルアロマ」は横軸において近接しているため、この4商品2組については順位が逆転してもOK
各軸を得点でソートしたのが次の図です。

縦軸の商品順序は完全に一致しています。横軸上では「ボスプレッソ」と「ボスプレッソトリプルアロマ」、「微糖・深煎り」と「地中海ブレンド」が順序が逆転しておりますが、これは事前に予測していた誤差範囲内です。
以上から、十分にサントリーデータと一致しているマッピングを得ることができました。
改めてポジションを見てみると、ジョージアエメラルドマウンテンやワンダモーニングショット、レインボーマウンテンなど有名どころは狭いカテゴリーで戦っていることがわかります。
一時期CMで「売れとるからうまいやろ」みたいなセリフがありましたが、この3商品は全体から見れば味に大差なく、後はマーケティングパワーの差 が売上に貢献しているのでしょう。もちろんわずかな差が大きな差を生むこともありますし、売れてるからうまいと思う人もいる訳ですから間違っているとは言 いませんが・・・。
あとはこのマップに、依頼元の製品データをプロットして報告書を作成し、納品となりました。
私たちは納品後にお客様に1つの提案をいたしました。
それが「官能評価の社内体制の確立」です。
理由は3つです。
1つ目は、評価ノウハウの蓄積により商品開発の期間短縮や試作コストの削減、前回ご紹介した品質規格の合理的設定が容易になるなどメリットが大きいことです。
2つ目は、仮にセンサー等の機器を導入するとしても官能評価のノウハウは十分生かされるからです。たとえばあるセンサーでは、 センサーのアウトプットだけでは意図するところを表現することができません。センサーのアウトプットは○○mvなどで、風味特性を直接明らかにはしてくれ ないようです。一方、甘味や酸味など特定して検出するセンサーもありますが、それですべての風味をまかなえるわけではありません。将来的には人間と同じよ うに判断するようになるかもしれませんが、当面はヒトの判断が必要となります。その際にセンサーのアウトプットの意味を汲み取るために官能評価のノウハウ が必須となります。
最後は、何よりも安く上がるからです。社員をパネルとして活用することでパネル人件費を抑え、運営の仕方によっては社員のモチベーションアップにもつながります。
このようなメリットのある「官能評価の社内体制の確立」ですが、弊社ではパッケージサービスとして提供しております。6ヶ月間で2名の官能評価技術者と社内パネルの構築を実現します。
詳しくは弊社までお問合せください。
さて、前々回と今回の2回に分けて評価事例を紹介しました。分析型官能評価にありがちな厳密な言葉の定義や軸の意味合いよりも、相対的に自社の製 品が他社商品群の中でどのようなポジションにあるかを明らかにすることを目的にした事例です。その中で主成分分析やPLS回帰分析をご紹介いたしました。 また、簡単ですがソフトウェアについても言及してみました。
商品ポジショニングや特定データ(例えばセンサーや成分分析の結果)との相関の案件が増えてきているのでトレンドの事例として紹介いたしました。
最後にサントリーさん、モンドセレクション3年連続最高金賞おめでとうございます。
それでは、また!