
◆◇◆◇◆◇◆官能評価TT通信No.35◆◇◆◇◆◇◆
さて、今回のテーマは「プリファレンスマッピング」です。
官能評価においてもデータとデータを結合することは結構あります。
前回の評価事例-後編でご紹介した「他社データと自社データの結合」も1つの方法です。
今回は官能データと嗜好データとの結合、いわゆる「プリファレンスマッピング」のお話です。
弊社で扱う「データ結合」案件で最も多いのが官能データと嗜好データ(マーケティングデータ)の結合で、次が官能データと機器データになります。やはり各企業が市場の声に耳を傾けているという姿勢のあらわれでしょうか。
さて、プリファレンスマッピングです。
プリファレンスマッピングといえばGreenhoff & Macfieの「Preference mapping」に起源をもちますが、現在では様々なバリエーションが発表されています。
Greenhoff K. & Macfie H. J. H. (1994). Preference mapping in practice. In Measurement of food preferences, ed. H. J. H. MacFie and D. M. H. Thomson.Blackie academic & professional. London.
プリファレンスマッピングには大きく分けて2つの種類があります。
(1)内的プリファレンスマッピング(Internal Preference Mapping ; IPM)
(2)外的プリファレンスマッピング(External Preference Mapping ; EPM)
IPMは、嗜好データの主成分分析です。データの形としては、消費者とプロダクトの2元表に消費者が回答した嗜好評価の値を入れたものになります。消費者をグループ分けすることもあります。表現方法は、主成分分析の結果をバイプロットします。
※バイプロット:主成分得点とベクトルを同一グラフに表示。Gabrielバイプロットとも呼ばれます。
EPMは、官能データと別にとられた(外部の)嗜好データを個別に分析し、結合する方法です。使用する分析手法には、マッピングのために主 成分分析や一般化プロクラステス分析(Generalized Procrustes Analysis : GPA)などを用います。嗜好データの分類に自己組織マップやk-means、階層型などのクラスター分析を用いることがあります。表現方法は、やはりこ ちらも基本はバイプロットになります。
一般的にプリファレンスマッピングとはEPMを意味しますので、本稿でもEPMについて進めていきます。
皆さんがEPMを検討するのは、おそらく次の3つが主要な目的の場合でしょう。
(1)官能属性と嗜好度を関連付ける
(2)消費者グループ別に嗜好の違いを表現すること
(3)視覚的に表現する
個別にみてみると大した事はしておりません。
(1)の官能属性と嗜好度を関連付けるだけなら、回帰分析やその他の手法でも可能です。
(2)の消費者グループ別に嗜好の違いを表現するだけなら、クラスター分析でグルーピングし、嗜好順序で表現することも可能です。
では、なぜEPMなのか。
それはEPMが視覚的に表現するのが得意だからです。
EPMの基本的な分析フローを見てみましょう
ステップ1 官能データから商品マップを作成する(主成分分析)
ステップ2 嗜好データから消費者をグルーピングする(クラスター分析)
ステップ3 ステップ1の「主成分得点」とステップ2の「グループ分けされた消費者の嗜好データ」を結合
ステップ4 嗜好データを目的変数とした回帰分析など(PLS回帰分析、ANN)
ステップ5 バイプロットに表示する
見たところ簡単そうですが、プリファレンスマッピングは日本の企業ではあまり使われていない手法の1つです。
おそらくステップ4の分析が面倒なためではないかと考えてます。ソフトウェアがあれば簡単なのでしょうが、先日試用版で試したプリファレンスマッ ピングが分析メニューに入っている統計解析ソフトでも手間取ってしまいました。(Rの官能評価パッケージ「SensoMineR」にあるcarto関数で さくっと分析できますが、Rに慣れていないと手間取ります)
現時点で私の意見は「プリファレンスマッピング(EPM)をやりたければ機能付のソフトウェアを使うのが早い」ということです。
時間と知識があれば、エクセルやR、その他の統計ソフトでも分析することは可能ですが、試行錯誤の時間と得られる情報量を考えればプリファレンスマッピングにこだわる必要はないでしょう。
そこで今回は主成分分析とクラスター分析ができる統計ソフトとエクセルがあれば誰でもできる「選好等高線図(Preference Contour Mapping)」をご紹介しましょう。ステップ4を行わずに3つの目的を果たしています。
使用したデータは、フリーウェア統計ソフトRの官能評価パッケージ「SensoMineR」 に含まれるチョコレート6種のサンプルデータ(sensochoc:官能データ、hedochoc:嗜好データ )を使用しました。分析に使用したソフトはJMPです。主成分分析とクラスター分析ができればソフトは何でもかまいません。今回はJMPでグラフ作成まで やりましたが、使用ソフトのグラフ作成機能がわかり難いなら、作図はエクセルでも大丈夫です。
「選好等高線図(Preference Contour Mapping)」の分析フローは4つのステップからなります
ステップ1 官能データから商品マップを作成する(主成分分析)
ステップ2 嗜好データから消費者をグルーピングする(クラスター分析)
ステップ3 ステップ1の「主成分得点」とステップ2の「グループ分けされた消費者の嗜好データ」を結合
ステップ4 等高線図に表示する(主成分1、主成分2、嗜好データ)
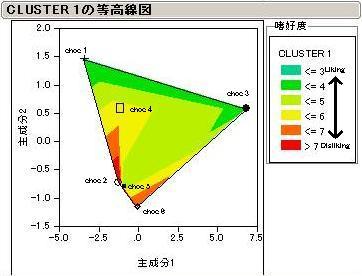
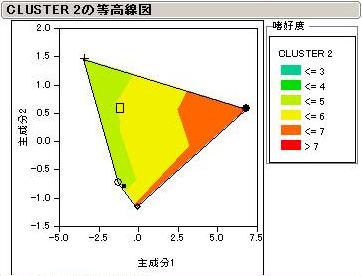
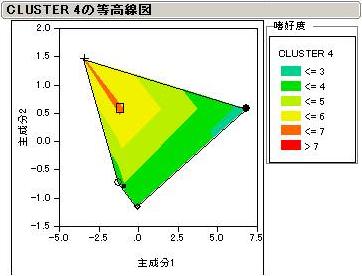
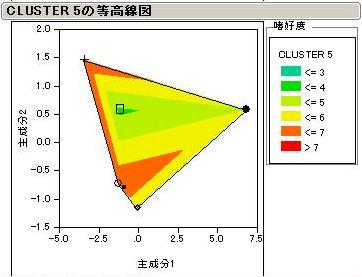
7つに分類された消費者クラスターごとの結果を見てみましょう。商品名は消費者Cluster1のみに表示してありますが、他も同様の配置となっています。
色は嗜好度を表しています。嫌い(Disliking)なほど赤くなります。尚、本結果自体に意味があるのではなく、読み方の参考としてご覧下さい。
 |
 |
|
 |
 |
|
 |
 |
|
 |
見方ですが、まず最初のグラフ(Cluster1)を見てみましょう。
各商品が2次元上に配置されています。軸の意味を知りたい場合はステップ1で得られた主成分分析の結果から読み取ります。
そして、商品で囲まれたエリアには商品ごとの嗜好度について等高線が引かれています。このグラフでは等高線の間を色分けしてあります。
色合いが同じところでは、同程度の嗜好度であると考えられます。
どうやらCluster1の消費者は、choc2,5を嫌いchoc1および3の方へ行くと嗜好が高まる傾向があるようです。
傾向を知りたい場合、等高線に基づいてベクトル線を描き、原点に移動して表示すると便利です(このベクトルは、EPMのバイプロットにおけるベクトルと同様の意味になります)。
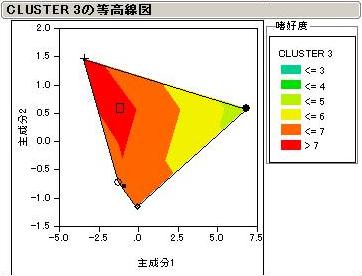
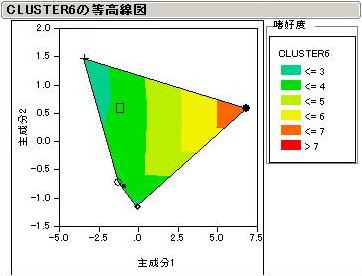
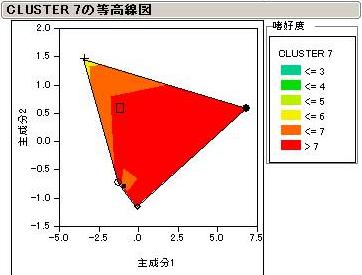
全部は説明できないので、特徴のあるCluster3とCluster6について見てみましょう。
Cluster3はchoc1,4をとても嫌っています。等高線から読み取ると、ちょうどX軸(主成分1)に平行なベクトルが描けます。
このことからCluster3をターゲットとするなら主成分1の得点が高い風味属性のチョコレートが好まれそうです。
Cluster6はchoc3を嫌いな頂点として、きれいに等高線が引かれています。
等高線から、choc3からchoc2,5,6へベクトル線が引けます。どうやらCluster6の嗜好度を高めるには、主成分1と2の両方の得点が低い風味属性のチョコレートを開発するのがよさそうです。
このように主成分分析とクラスター分析、そして等高線図で消費者別の嗜好傾向が視覚的にもわかりやすく表現することができました。
最後に注意なのですが、クラスター分析の結果から得られた消費者集団がどのような特性であるかは明らかにはなっておりません。
そこで2つの方法が考えられます。
1.グルーピング後に消費者の属性(デモグラフィック属性など)を分析する。
2.最初から消費者属性によってグルーピングする。
1の場合、グループを特徴付ける結果が得られればマップが役立ちますが、特徴がなければただ分類されただけになります。
お薦めは最初から消費者属性(例えば、性別や年齢層など)でグルーピングすることです。
今回は官能データと嗜好データを結合するプリファレンスマッピングの概要と、簡易版としての「選好等高線図(Preference Contour Mapping)」をご紹介しました。
現実には、売れる商品を開発するために「美味しい」を目的変数にした分析では足りません。さらに「購買意欲・行動」まで踏み込んだ分析へと移行する必要があります。
これが「”おいしい”を”売れる”へ」をモットーに、弊社が推し進めている「売るための官能評価」です。
それでは、また!