
NappingやSortingはホリスティック法と呼ばれ、総合的・全体的(Holistic)な評価方法として用いられます。
プロダクトマップを作る方法としては早く簡単なので、ラピッドメソッドとも呼ばれます。
最近、実務でホリスティック法を使う企業が増えてきたと感じています。今年夏頃に官能評価学会の企業部会がテーマとして取り上げたのも大きいのでしょう。
ホリスティック法はパネリストが行う評価方法は記述型官能評価(DA)に比べて簡単なのですが、データの解析が厄介です。
ホリスティック法のデータ解析にはMFA、GPA、STATISなどが使われます。MFAなどの手法は、複数のマップから平均的マップ(「コンフィグレーションマップ」または「コンセンサスマップ」などと呼ばれます)を計算します。得られたマップがいわゆる「プロダクトマップ」として使われます。
SensoMineRではRコマンダーのメニュー(下記)からNappingの解析ができます。※弊社推奨のインストール方法でRコマンダーから操作可能です。
SensoMineR>Holistic approches>Procrustes multiple factor analysis
Rなのにマウス操作なので簡単に解析できます。そして多くのグラフが表示されます。初めての方には多すぎるくらいですが・・・。
しかし、プロダクトマップの各座標データが得られません。
解析結果のオブジェクトresultsの中身を確認してもRV係数が表示されるだけです。
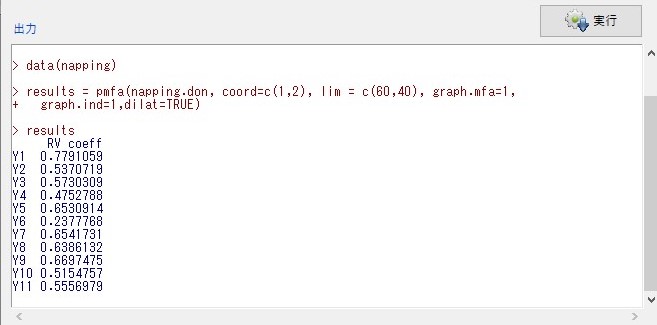
座標データは、一番データとしてほしいところです。エクセルやパワーポイントで加工する上で必要なデータです。
実はRコマンダーから実行したコマンドはpmfa関数といいます。このpmfa関数では座標データが残らないのです(コードを見ると、そもそも座標データを保存するようにプログラムされていない)。
そこで座標データを取得するためにはpmfa関数ではなく、pmfa関数の内部で行っている多因子分析(MFA)を自分で実行して取得します。
データセットを読み込んでからFactoMineRのRコマンダーメニューから下記を実行します。
※「RcmdrPlugin.FactoMineR」パッケージをインストール、Rコマンダーからパッケージを読み込みます。

FactoMineR>Multiple Factor Analysis
回答者ごとのデータ(X,Y)を各グループとして登録していきます。
その際「各回答者のXY座標データは標準化しないのがポイントです!」
Scale the variable … をNoとして設定します。
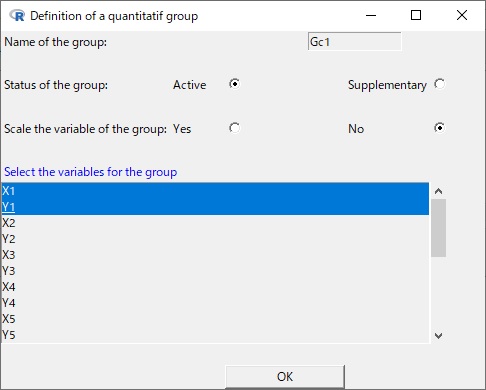
ワードカウントデータ(UFPのデータ)がある場合、こちらは標準化します。
Scale the variable … をYesとして設定します。
Outputsボタンからオプション画面を表示します。
Print results on a ‘csv’ … に出力するファイル名を入力します。
その際、「●●.txt」と入力します。
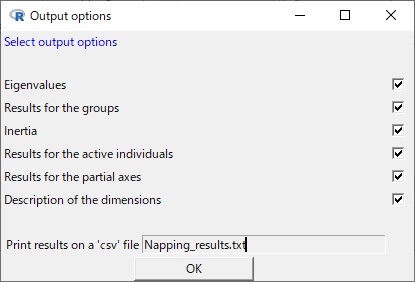
CSVと書いてありますが、実際は「;」で区分けされていますので、日本語環境ではCSVファイルで保存してしまうとデータ構造が崩れてしまいます。ですからtxtとして保存し、読み込むときに「;」を区分記号として設定して読み込ます。
詳しい操作方法は弊社テキストに記載されていますので、ご興味のある方は下記テキストをご検討下さい。
SensoMineRでホリスティック分析入門テキスト(Napping/Projective Mapping)
SensoMineRによるNappingの座標データ取得方法をご紹介しました。