ハッピーホリディ
今年も残すところあと1週間となりました。
今年の官能評価関連の状況を振り返りたいと思います。
まず、第一に今年大きなニュースだったのが「トマト知財裁判」です。
トマトジュース大手の2社による知財裁判(特許)で、特許の無効を求めた裁判でした。
官能評価担当者として注意すべき点は、官能評価の「定量性・客観性の問題」が取り上げられて争点ともなっていることです。
食品の特許申請では官能評価データを使用することが多いですが、申請に用いる官能評価データの「定量性・客観性」が更に求められるようになるでしょう。
特に飲料食品メーカーでは知財部門と官能評価部門が連携をとることはほとんどないため、官能評価担当者自身がこれらの情報にアンテナを張っておきましょう。
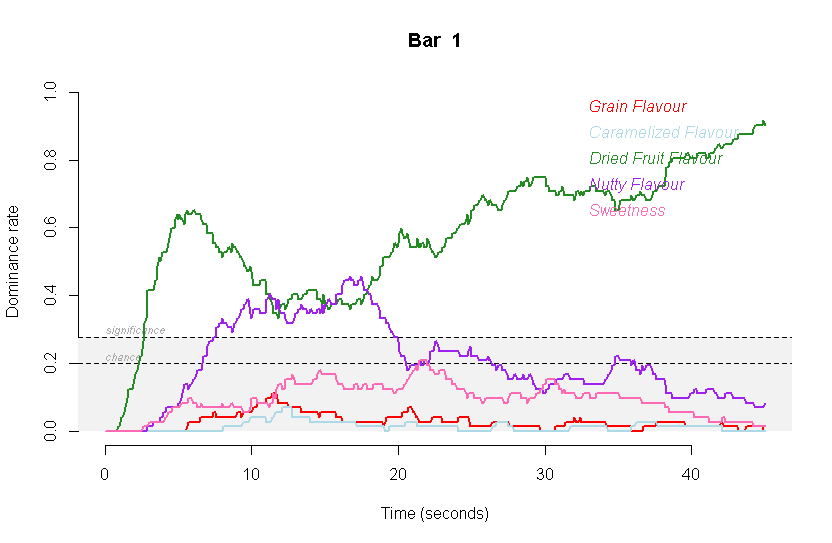
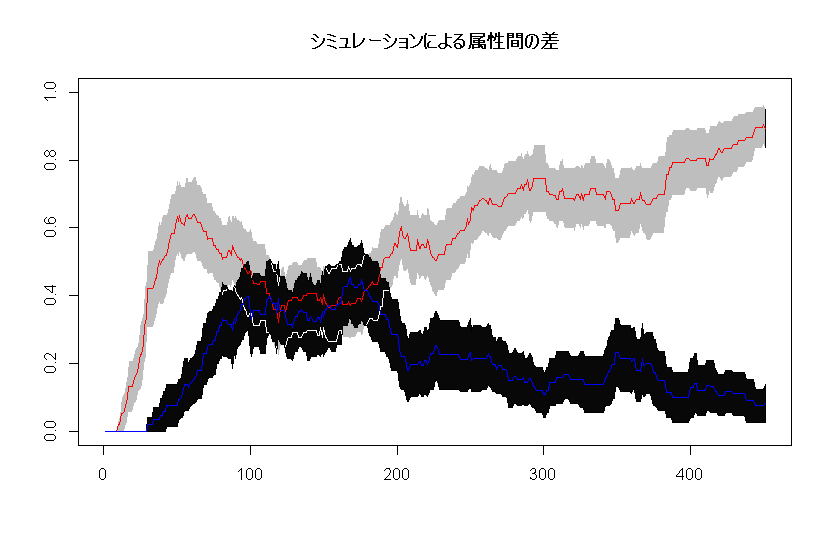
次に、時系列手法の活況が引き続き続いていることです。
数年前からのTDSを皮切りに、TCATA、TDLそしてリバイバルでTimeIntensityの活用が活発化しております。
ソフトウェアの充実に加えて、国内企業による研究も次々と発表されているのが追い風となっているのでしょう。
また、TDSやTCATAを実際に使ってみることでTimeIntensityのメリットも再評価されてTimeIntensityも活用されています。
お蔭さまでダイナミック官能評価ソフトウェアMagicSenseもご活用頂いております。
今後ともよろしくお願いいたします。
最後は、私の実感としてですが、国内企業の官能評価関連の予算が増加しているように感じております。
正直なところ、従来の官能評価の予算は少なく、広告宣伝費はもちろんのことマーケティングリサーチの予算に比べても大幅に少ないのが担当者の悩みの種でした。
これが徐々に予算枠が増えてきているように感じております。
背景として、国内企業の多くは新しいことに予算を付けるよりも「競合他社がやっているが自社ではやっていない」という案件には予算が付きやすいように思います。
時系列手法の活況の影響でもありますが、競合他社が新しい手法を導入したり、システムを購入したりすると予算が付くというお話を伺います。
担当者としては予算申請時期には競合他社の動向にも目を向けてみると予算が通りやすくなるかもしれませんね。
2017年のISO更新情報です。
ISO6658は官能評価の大元の規格です。全体的な章立てが再構成されてページが増えています。テトラッド手法が記載されました。
ISO6658とISO10399はページ数が増えていますが、ISO10399は減少しています。
●ISO 6658:2017 官能試験-方法論-一般的手引
Sensory analysis — Methodology — General guidance
●ISO 8588:2017 官能試験-方法論-A-非A試験
Sensory analysis — Methodology — “A” – “not A” test
●ISO 10399:2017 官能試験-方法-1対2点試験法
Sensory analysis — Methodology — Duo-trio test
あと1週間で今年も終わりです。よいお年をお迎えください。